
https://opensource.com/article/20/2/c-data-science
Using C and C++ for data science
While languages like Python and
opensource.com
C99 및 C++11을 사용하여 일반적인 데이터 사이언스 작업을 수행해 봅시다.

Python 및 R과 같은 언어가 데이터 사이언스에 점점 더 많이 사용되고 있기는 하지만 C 및 C++는 효율적이고 효과적인 데이터 사이언스을 위한 강력한 선택이 될 수 있습니다. 이 기사에서는 C99와 C++11을 사용하여 다음으로 설명 할 Anscombe의 4중주 데이터셋을 사용하는 프로그램을 작성할 것입니다.
검토할 가치가 있는 Python 및 GNU Octave기사를 다루면서 지속적으로 언어를 배우는 동기에 대해서 글을 썼습니다. 여기 모든 프로그램은 그래픽 사용자 인터페이스(GUI)가 아닌 명령줄에서 실행됩니다. 전체 예제는 polyglot_fit 저장소를 이용하면 사용할 수 있습니다.
프로그래밍 작업
이 시리즈에서 작성 하게 될 프로그램은:
- CSV 파일에서 데이터를 읽습니다.
- 데이터를 직선으로 보간합니다(즉, f(x)=m ⋅ x + q)
- 결과를 이미지 파일로 플롯합니다.
이 순서는 많은 데이터 과학자들이 마주하는 일반적인 상황입니다. 예제 데이터는 아래 표에 표시된 Anscombe의 4중주의 첫 번째 세트입니다.
이 데이터는 직선으로 피팅하면 동일한 결과를 제공하지만 플롯이 매우 다른 인공적으로 구성된 데이터 세트입니다. 데이터 파일은 열을 구분하는 기호로 탭을 사용하고 있으며, 몇 줄의 머릿글을 가지고 있는 텍스트 파일입니다. 이 작업은 첫 번째 집합(즉, 처음 두 열)만 사용 할 것입니다.
안스콤의 사중주
|
I
|
II
|
III
|
IV
|
||||
|
x
|
y
|
x
|
y
|
x
|
y
|
x
|
y
|
|
10.0
|
8.04
|
10.0
|
9.14
|
10.0
|
7.46
|
8.0
|
6.58
|
|
8.0
|
6.95
|
8.0
|
8.14
|
8.0
|
6.77
|
8.0
|
5.76
|
|
13.0
|
7.58
|
13.0
|
8.74
|
13.0
|
12.74
|
8.0
|
7.71
|
|
9.0
|
8.81
|
9.0
|
8.77
|
9.0
|
7.11
|
8.0
|
8.84
|
|
11.0
|
8.33
|
11.0
|
9.26
|
11.0
|
7.81
|
8.0
|
8.47
|
|
14.0
|
9.96
|
14.0
|
8.10
|
14.0
|
8.84
|
8.0
|
7.04
|
|
6.0
|
7.24
|
6.0
|
6.13
|
6.0
|
6.08
|
8.0
|
5.25
|
|
4.0
|
4.26
|
4.0
|
3.10
|
4.0
|
5.39
|
19.0
|
12.50
|
|
12.0
|
10.84
|
12.0
|
9.13
|
12.0
|
8.15
|
8.0
|
5.56
|
|
7.0
|
4.82
|
7.0
|
7.26
|
7.0
|
6.42
|
8.0
|
7.91
|
|
5.0
|
5.68
|
5.0
|
4.74
|
5.0
|
5.73
|
8.0
|
6.89
|
C의 방식
C는 범용 프로그래밍 언어로 오늘날 가장 널리 사용되는 언어 중 하나입니다(TIOBE 인덱스, RedMonk 프로그래밍 언어 순위, 프로그래밍 언어 인덱스 인기도 및 GitHub의 Octoverse 상태 데이터에 근거함).
꽤 오래된 언어(약 1973년)이며 많은 성공적인 프로그램이 이 언어로 작성되었습니다(예: Linux 커널과 Git).
또한 메모리를 직접 조작하는 데 사용되므로 컴퓨터의 내부 동작과 가장 가까운 언어 중 하나입니다. 이 언어는 컴파일 되는 언어입니다. 따라서 소스 코드는 컴파일러에 의해 기계 코드로 변환되어야 합니다. 표준 라이브러리는 기능이 작고 가볍기 때문에 없는 기능들을 제공받기 위해 다양한 라이브러리들이 개발되었습니다.
주로 성능 때문에 숫자 연산에 가장 많이 사용하는 언어입니다. 많은 boilerplate code 가 필요하기 때문에 사용하기 다소 지루하지만 다양한 환경에서 잘 지원됩니다.
C99 표준은 멋진 기능들이 추가 되었고, 컴파일러에서 잘 지원하는 최신 개정판입니다.
초보자와 고급 사용자 모두가 따라할 수 있도록 C 및 C++ 프로그래밍의 필요한 배경을 다루어 볼 것입니다.
설치
C99로 개발하려면 컴파일러가 필요합니다. 나는 보통 Clang을 사용하지만 GCC는 또 하나의 유효한 오픈 소스 컴파일러입니다. 나는 선형 피팅을 위해 GNU Scientific Library를 사용하기로 했습니다. 플로팅을 위해 합리적인 라이브러리를 찾을 수 없었기 때문에 이 프로그램은 외부 프로그램인 Gnuplot에 의존합니다. 이 예제에서는 BSD(Berkeley Software Distribution)에 정의된 동적 데이터 구조를 사용하여 데이터를 저장하기도 합니다.
다음 명령을 실행하면 Fedora에 쉽게 설치 됩니다:
sudo dnf install clang gnuplot gsl gsl-devel주석 코드
C99에서 주석은 줄의 시작 부분에 //를 넣어 서식을 지정하면, 인터프리터에서 나머지 줄은 버려집니다. 또는 /*와 */ 사이의 항목도 마찬가지로 버려집니다.
// This is a comment ignored by the interpreter.
/* Also this is ignored */필요한 라이브러리들
라이브러리는 다음 두 부분으로 구성됩니다:
- 함수들에 대한 설명이 포함된 헤더 파일
- 함수들의 정의가 포함된 소스 파일
헤더 파일은 소스에 포함되며 라이브러리의 소스는 실행 파일에 연결됩니다. 따라서 이 예제에 필요한 헤더 파일은 다음과 같습니다:
// Input/Output utilities
#include <stdio.h>
// The standard library
#include <stdlib.h>
// String manipulation utilities
#include <string.h>
// BSD queue
#include <sys/queue.h>
// GSL scientific utilities
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>메인 함수
C에서 프로그램은 반드시 main()이라는 특수 함수 안에 있어야 합니다.
int main(void) {
...
}이것은 소스 파일에서 찾아 실행 될 어떠한 코드 든지 마지막 자습서에서 다룬 Python과 다릅니다.
변수 정의
C에서 변수는 사용되기 전에 선언되어야 하며 유형과 결합되어야 합니다. 당신이 변수를 사용하고자 할 때마다 어떤 종류의 데이터를 저장할지 결정해야만 한다는 뜻입니다. 변수를 상수 값으로 사용하려는 경우 지정할 수도 있습니다. 이는 필요하지 않지만 컴파일러는 이 정보를 활용할 수 있습니다.
저장소의 fitting_C99.c 프로그램에서:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;C의 배열은 길이를 미리(즉, 컴파일하기 전에) 결정해야 한다는 점에서 동적이지 않습니다:
int data_array[1024];일반적으로 파일에 얼마나 많은 데이터 포인트가 있는지 모르기 때문에 singly linked list을 사용하십시오. 이는 무한정 증가할 수 있는 동적 데이터 구조입니다. 다행스럽게도 BSD는 linked list을 제공합니다. 다음은 예제 정의입니다:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);이 예는 x 값과 y 값을 모두 포함하는 구조화된 값으로 구성된 data_point 목록을 정의합니다. 문법은 다소 복잡하지만 직관적이며 자세히 설명하면 너무 장황 할 것입니다.
결과 출력
터미널로 인쇄하려면 Octave의 printf() 함수(첫 번째 기사에서 설명)처럼 동작하는 printf() 함수를 사용할 수 있습니다:
printf("#### Anscombe's first set with C99 ####\n");printf() 함수는 인쇄된 문자열 끝에 개행을 자동으로 추가하지 않으므로 추가해야 합니다.
첫 번째 인수는 다음과 같이 함수에 전달할 수 있는 다른 인수에 대한 형식 정보를 포함할 수 있는 문자열입니다:
printf("Slope: %f\n", slope);데이터 읽기
이제 어려운 부분입니다. C에서 CSV 파일 구문 분석을 위한 몇 몇 라이브러리가 있지만 Fedora 패키지 저장소에 있을 만큼 안정적이거나 대중적인 것은 없었습니다. 이 튜토리얼에 대한 라이브러리 종속성을 추가하는 대신 이 부분을 직접 작성하기로 결정했습니다. 다시 말하지만, 세부 사항으로 들어가는 것은 너무 장황할 것이므로 일반적인 개념만 설명하겠습니다. 간결함을 위해 소스의 일부 줄은 무시되지만 저장소에서 전체 예제를 찾아 볼 수 있을 것입니다.
먼저 입력 파일을 엽니다:
FILE* input_file = fopen(input_file_name, "r");그런 다음 오류가 발생하거나 파일이 끝날 때까지 파일을 한 줄씩 읽어 들입니다:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}getline() 함수는 POSIX.1-2008 표준에서 최근 추가된 멋진 함수입니다. 이 함수는 파일의 전체 줄을 읽어내고 이에 대한 필요한 메모리 할당도 처리할 수 있습니다. 그런 다음 각 줄은 strtok() 함수를 사용하여 토큰으로 나누어 줍니다. 토큰을 반복하면서 당신이 원하는 열을 선택합니다:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}마지막으로 x 및 y 값이 선택되면 linked list에 새 데이터 포인트를 삽입합니다.
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);malloc() 함수는 새 데이터 포인트에 대한 일부 영구 메모리를 동적으로 할당(예약)합니다.
피팅 데이터
GSL 선형 피팅 함수 gsl_fit_linear()는 간단한 배열을 입력으로 예상합니다. 따라서 생성하는 배열의 크기를 미리 알 수 없으므로 메모리를 수동으로 할당해야 합니다:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);그런 다음 linked list를 반복하면서 관련 데이터를 배열에 저장합니다:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}이제 linked list로 완료되었으므로 정리해 줍니다. 메모리 누수를 방지하기 위해 수동으로 할당된 메모리를 항상 해제하십시오. 메모리 누수는 정말 정말 정말 안되요. 메모리가 해제되지 않을 때마다 정원 그놈(페도라)은 머리를 잃어버릴 것입니다:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}진짜 마지막으로(!) 데이터를 피팅합니다.
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);플로팅
플로팅을 위해 외부 프로그램을 사용해야만 합니다. 그러기위해선 이 피팅 함수를 외부 파일에 저장하십시오:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}두 파일을 플로팅하기 위한 #Gnuplot 명령은 다음과 같습니다.
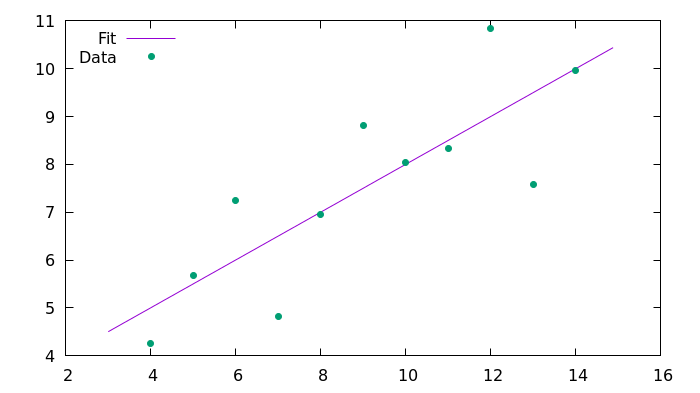
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'결과
프로그램을 실행하기 전에 반드시 컴파일해야 합니다.
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99This command tells the compiler to use the C99 standard, read the fitting_C99.c file, load the libraries gsl and gslcblas, and save the result to fitting_C99. The resulting output on the command line is:
이 명령은 컴파일러에게
- C99 표준을 사용하고,
- fitting_C99.c 파일을 읽어들이고,
- gsl 및 gslcblas 라이브러리를 로드하고,
- 그 결과를 fitting_C99에 저장하도록
지시 했습니다.
명령줄의 결과 출력은 다음과 같습니다.
#### Anscombe's first set with C99 ####
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421다음은 Gnuplot으로 생성된 결과 이미지입니다.
C++11 방식
C++는 오늘날 가장 널리 사용되는 언어 중 하나인 범용 프로그래밍 언어입니다. 객체 지향 프로그래밍(OOP)에 중점을 둔 C(1983년)의 계승으로 만들어졌습니다. C++는 일반적으로 C의 상위 집합으로 간주되므로 C 프로그램은 C++ 컴파일러로 컴파일할 수 있어야 합니다.
다르게 동작하는 몇 가지 코너 케이스가 있기 때문에 이 말은 정확히 사실이 아닙니다. 내 경험상 C++는 C보다 boilerplate 코드가 덜 필요하지만 객체를 개발하려는 경우 문법이 더 어렵습니다. C++11 표준은 몇 가지 멋진 기능을 추가되었고 컴파일러에서 어느 정도 지원하는 최신 개정판입니다.
C++은 대부분 C와 호환되기 때문에 둘 사이의 차이점만 강조하겠습니다. 이 부분에서 다루지 않았다면 그 외는 C에서와 같다는 뜻입니다.
설치
C++ 예제의 종속성은 C 예제와 동일합니다. Fedora에서 다음을 실행합니다:
sudo dnf install clang gnuplot gsl gsl-devel필요한 라이브러리
라이브러리는 C에서와 같은 방식으로 작동하지만 include 지시문은 약간 다릅니다.
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}#GSL 라이브러리는 C로 작성되었으므로 컴파일러에 이 특성을 알려야 합니다.
변수 정의
C++는 C보다 더 많은 기능을 가진 문자열 유형을 지원하고, C보다 더 많은 데이터 유형(클래스)을 지원합니다. 그에 따라 변수의 정의를 업데이트합니다.
const std::string input_file_name("anscombe.csv");문자열과 같은 구조화된 객체의 경우 = 기호를 사용하지 않고 변수를 정의할 수 있습니다.
결과 출력
printf() 함수를 사용할 수 있지만 cout 객체가 더 관용적입니다. << 연산자를 사용하여 cout으로 인쇄하려는 문자열(또는 객체)을 나타냅니다.
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
...
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;데이터 읽기
스키마는 이전과 동일합니다. 파일은 한 줄씩 열리고 읽히지만 다른 문법을 사용하고 있습니다:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}라인 토큰은 C99 예제와 동일한 기능으로 추출됩니다. 표준 C 배열을 사용하는 대신 두 개의 벡터를 사용하십시오. 벡터는 명시적으로 malloc()을 호출하지 않고 메모리의 동적 관리를 허용하는 C++ 표준 라이브러리의 C 배열 확장입니다:
std::vector<double> x;
std::vector<double> y;
// Adding an element to x and y:
x.emplace_back(value);
y.emplace_back(value);피팅 데이터
C++에서 피팅의 경우 벡터가 연속 메모리를 갖도록 보장되므로 list를 반복할 필요가 없습니다. 벡터 버퍼에 대한 포인터를 피팅 함수에 직접 전달할 수 있습니다:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
std::cout << "Correlation coefficient: " << r_value << std::endl;플로팅
플로팅은 이전과 동일한 접근 방식으로 수행됩니다.
파일에 쓰기:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
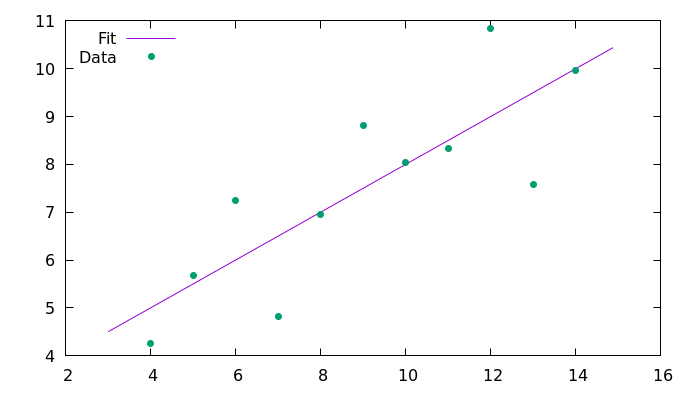
output_file.close();그런 다음 플로팅에 Gnuplot을 사용하십시오.
결과
프로그램을 실행하기 전에 유사한 명령으로 컴파일해야 합니다.
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11명령줄의 결과 출력은 다음과 같습니다.
#### Anscombe's first set with C++11 ####
Slope: 0.500091
Intercept: 3.00009
Correlation coefficient: 0.816421그리고 이것은 Gnuplot으로 생성된 결과 이미지입니다.
결론
이 문서에서는 C99 및 C++11의 데이터 피팅 및 플로팅 작업에 대한 예제를 만들어 보았습니다. C++은 대체로 C와 호환되므로 이 기사에서는 두 번째 예제를 작성하기 위해 C++의 유사점을 활용했습니다. 일부 측면에서 C++는 명시적으로 메모리를 관리해야 하는 부담을 부분적으로 덜어주기 때문에 사용하기가 더 쉽습니다. 그러나 문법은 OOP에 대한 클래스 작성 가능성을 도입하기 때문에 더 복잡합니다. 그러나 OOP 접근 방식을 사용하여 C로 소프트웨어를 작성하는 것은 여전히 가능합니다. OOP는 프로그래밍 스타일이므로 모든 언어에서 사용할 수 있습니다. GObject 및 Jansson 라이브러리와 같이 C에서 OOP를 활용한 몇 가지 훌륭한 예들이 존재 합니다.
숫자 계산의 경우 더 간단한 문법과 광범위한 지원으로 인해 C99에서 작업하는 것을 선호합니다. 최근까지 C++11은 널리 지원되지 않았고 이전 버전의 힘든 곳은 피하는 경향이 있었습니다. 보다 복잡한 소프트웨어의 경우 C++가 좋은 선택이 될 수 있을 것입니다.
당신은 데이터 사이언스에도 C 또는 C++를 사용하십니까?
의견에 경험을 공유 해 주십시오.
'프로그래밍' 카테고리의 다른 글
| 웹 요청 순서 시각화 (0) | 2022.12.11 |
|---|---|
| 뮤텍스, 세마포어 그리고 끔찍한 헤어스타일 사이 (0) | 2022.12.10 |
| 테스트 오케스트레이션: What, Why, and How? (0) | 2022.12.06 |
| 세가지 점근적 분석법 (0) | 2022.12.05 |
| DS Algorithm (1) | 2022.12.01 |