Classifying Numbers and Clothing Items with Feedforward Neural Networks
With PyTorch, I built 2 feedforward neural network models: one that can classify numbers and another that can classify clothing items
medium.com
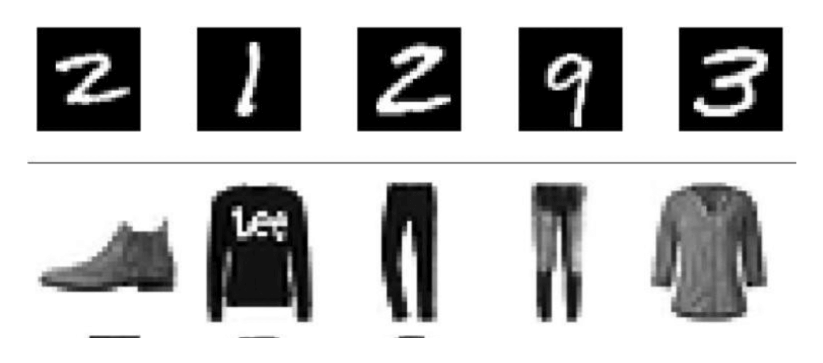
잠시 시간이 있으시면 그림의 위의 숫자를 읽어 보시기 바랍니다.
그런 다음 이 숫자들 아래 보이는 의류 품목을 확인해 보세요. 쉽네요.. 그쵸?
하지만, 이 작업이 어떤 사람들에게는 도전이 필요한 일이다라고 말하면 어떨까요? 어떤 사람들...그러니까 내 컴퓨터에서 말이죠.
잠깐만요, 컴퓨터 ... 뭐? 예! 최근에 제가 엄청난 열정을 갖고 있는 분야인 인공 지능에 뛰어들었을 때 저는 컴퓨터와 같은 기계가 모든 종류의 이미지를 분류할 수 있다는 것을 알아냈습니다.
나의 호기심으로 피드포워드 신경망 모델을 두 개를 만들어 볼까해요: 하나는 숫자를 분류할 수 있고 다른 하나는 의류 항목을 분류할 수 있도록 말이죠!
이 글에서는 다음에 항목에 대해서 통찰을 얻을 수 있을 것입니다:
- 피드포워드(feedforward) 신경망이란?
- 프로젝트의 데이터 세트
잠시 뒤로 돌아가… 피드포워드 신경망(feedforward neural network)이 무엇일까요?
이 신경망은 인공 지능(AI)에 포함 되며, 신경망의 일부분입니다.
신경망은 기본적으로 연결된 레이어를 형성하는 인공 뉴런 또는 노드로 구성됩니다.
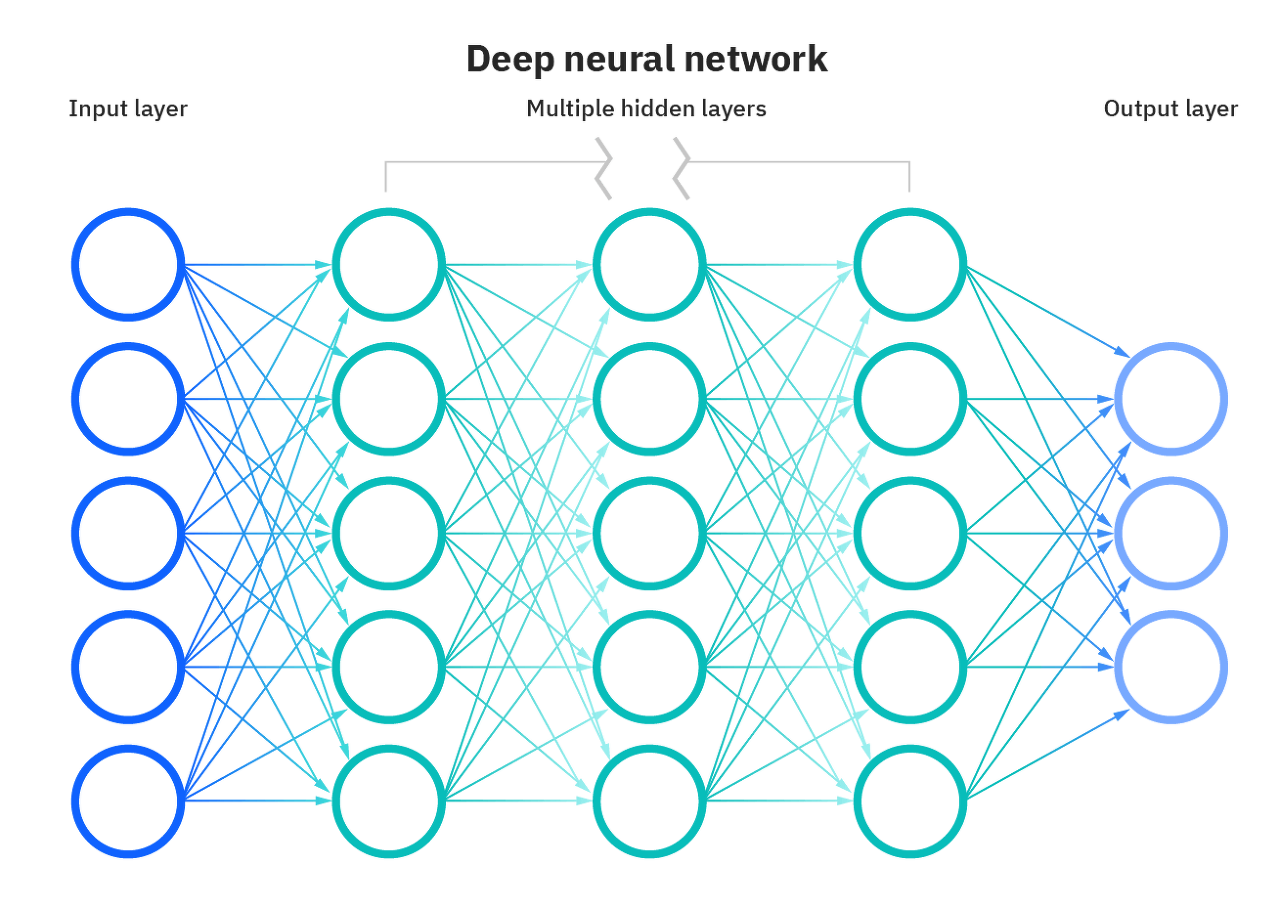
일반적으로 신경망은 위의 그림과 유사한 구조를 가지고 있습니다.
특정 데이터 군으로부터 어떤 데이터를 가져오는 입력 레이어에서 시작해서 최종 결과를 예측하는 출력 레이어로 끝납니다.
그 사이에는 네트워크에서 복잡한 계산을 수행하여 입력에서 출력 레이어으로 가는 은닉레이어(hidden layer)가 존재 합니다.
은닉 레이어(hidden layer)이 두 개 이상 있으면 그 신경망은 "심층-deep"이 됩니다.
노드들 연결하기
내 프로젝트는 즉, 네트워크가 한 방향으로만 이동한다는 뜻의 심층 피드포워드 신경망으로 구성되어 있습니다. 입력 레이어에서 수 많은 은닉 레이어(hidden layer)으로 그리고 출력 레이어로 앞 쪽 방향(forward)으로 이동합니다.
또한 훈련/테스트 시 앞뒤(forwards/backward)로 해당 모든 데이터의 하나의 완전한 실행 하는 각 에포크 후에 재설정되어 더 높은 정확도를 만들어 냅니다.
이 프로젝트의 데이터 세트
코드를 조금씩 살펴보기 전에 이러한 데이터세트로 수행되는 복잡한 구문을 쉽게 이해할 수 있도록 데이터세트에 대한 약간의 배경 정보에 대해서 말해 보겠습니다.
숫자와 의류 항목의 이미지들 둘 모두 신경망 모델을 계산하는 데 사용한 프로그래밍 프레임워크인 PyTorch의 torchvision 패키지에 존재 합니다.
torchvision 패키지를 살펴보면, MNIST 데이터 세트를 발견 할 수 있습니다.
그래서 한 모델에는 Number MNIST 데이터 세트를 사용했고, 다른 모델에는 Fashion MNIST 데이터 세트를 사용했습니다.
이 데이터 세트에는 각각 작은 정사각형 28 x 28 픽셀 이미지 60,000개가 포함되어 있습니다.
Number MNIST 데이터 세트에는 손으로 쓴 1자리 숫자(0–9)가 포함되어 있으며 모델의 결과물은 이 숫자들 중 하나입니다.
Fashion MNIST 데이터 세트는 출력으로 10개 classe/choice 항목을 포함하기 때문에 비슷하지만 데이터는 샌들, 티셔츠, 코트 등과 같은 의류 항목입니다.
이 숫자 중 데이터가 의류 항목임에도 불구하고 레이블은 숫자 0-9와 같은 형식입니다.

참고 하세요: 이러한 피드포워드 신경망의 코드들은 약간의 변경 사항을 빼면 매우 유사합니다.
다음 섹션들에서 이러한 내용을 확인 해 볼 것입니다.
제가 설명하는 코드는 작은 덩어리로 되어 있습니다. 하지만 내 전체 프로젝트가 어떻게 생겼는지 확인하고 사용/참조하려면 이 두 프로젝트에 대한 나의 Github 리포지토리를 확인보시면 됩니다.
더 고민하지 않고, 6개의 중요한 부분으로 나뉜 코드를 파헤쳐 봅시다:
- 라이브러리 가져오기(import)
- 데이터 세트 가져오기 및 교육 및 테스트 데이터 분할
- 신경망 모델 구축
- 모델 훈련
- 모델 테스트
- 시각화
단계 1: 라이브러리 가져오기(import)
%matplotlib inlineimport matplotlib.pyplot as plt
import torch
from torch import nn
from torch import optim
from torchvision import datasets, transforms
import helper이 단계에서 우리는 다음 단계들에서 사용할 필수 라이브러리들을 가져옵니다:
- torch — 다음 단계 프로세스에서 중요하므로 nn 및 optim을 포함, 수많은 패키지 포함 되어 있는 이 라이브러리가 우리는 필요 합니다.
- 또 앞서 언급한 대로 모델을 위한 필요 입력 데이터가 포함된 torchvision에서 데이터 세트를 가져와 이를 변환 합니다.
- helper 및 matplotlib.pyplot 라이브러리는 학습 손실과 같은 모델의 특성들을 설명하기 위해 데이터 및 그래프를 표시하는 데 사용됩니다(나중에 설명 할 것입니다).
The graph is right underneath the code cell
위 코드의 첫 번째 줄은 matplotlib 플로팅 명령의 출력이 Jupyter 노트북의 실행 중인 코드 셀 바로 아래에 인라인으로 표시 하라는 의미 입니다(오른쪽에 보여지듯이).
단계 2: 데이터 세트 가져오기 및 교육과 테스트 데이터로 분할
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])이 코드 조각은 나중 계산에 필요한 이미지를 더 적합하게 만들어 이미지를 변환하는 변수를 정의합니다.

- ToTensor() 함수는 0~255 범위의 픽셀을 0~1 픽셀 범위로 변환합니다.
- Normalize() 함수는 2개의 매개변수를 가지며, 이 경우에는 첫 번째와 두 번째 매개변수 모두 (0.5,)를 가집니다. 나중에 normalize 속성이 이미지 집합에 적용될 때 true이면 이미지들이 그레이스케일(회색)으로 조정 될 것입니다.
이 변수를 정의한 후, torchvision 내의 MNIST 데이터 세트에서 데이터를 가져와야 합니다:
trainset = datasets.MNIST(
'~/.pytorch/MNIST_data/',
download=True,
train=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=64,
shuffle=True)
testset = datasets.MNIST(
'~/.pytorch/MNIST_data/',
download=True,
train=False,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)위의 코드에는 2개의 유사한 부분이 있습니다: 하나는 교육 데이터용이고 다른 하나는 필요한 데이터를 다운로드하고 로드하는 테스트(평가 또는 검증과 동의어) 데이터용입니다.
- 데이터 세트를 다운로드하기 위한 다음 2개의 변수 입니다: trainset 및 testset. 트레이닝 세트와 테스트 세트들은 모두 데이터 세트에서 MNIST 데이터로의 경로, 데이터 세트를 다운로드해야 하는지 여부(True로 설정), 이미지 데이터를 변환해야 하는 transform 변수에서 변환을 포함하여 유사한 인수를 포함합니다. 하지만 테스트 세트에서와 다르게 훈련 세트에서는 해당 데이터가 훈련에 사용될 것이기 때문에 train 인수는 True 입니다.
- trainset과 testset 다음으로 각각 2개의 변수를 가집니다. 이러한 데이터 로더는 이러한 데이터 세트를 로드하고 배치 크기(한 번에 네트워크를 통과하는 샘플 수)를 변경하고 각 에포크 후에 데이터를 섞습니다.
참고: Fashion MNIST 데이터세트는 위에서 보는 구문이 똑 같으며, 대신 데이터세트의 경로만 "~pytorch/F_MNIST_data/"가 됩니다.
데이터가 제대로 다운로드되고 로드되었는지 확인하기 위해 다음을 실행 해 볼 수 있습니다:
images, labels = next(iter(trainloader))
helper.imshow(images[0], normalize=True)이 코드는 normalize=True이므로 다음과 같이 그레이스케일링된 훈련 데이터 세트에서 임의의 이미지(images[0])를 제공 합니다.

단계 3: 신경망 모델 구축
input_layer = 784
hidden_layers = [256, 128, 64]
output_layer = 10model = nn.Sequential(nn.Linear(input_layer, hidden_layers[0]),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(hidden_layers[0], hidden_layers[1]),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(hidden_layers[1], hidden_layers[2]),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(hidden_layers[2], output_layer),
nn.Softmax(dim=1))이 부분의 코드는 신경망 아키텍처를 이해 했다면 매우 직관적입니다.
모델을 만들 때 고려해야 할 세 가지 필수 질문이 존재 합니다:
- 몇 개의 레이어가 있어야 할까?
- 그 각각의 레이어에는 몇 개의 노드가 있어야 할까?
- 각 레이어에서 사용되는 transfer/activation 함수는 무엇인가?
이 코드는 각 레이어의 노드 수와 관련된 변수를 초기화한 다음 activation 및 dropout 함수와 같은 다양한 특징들을 추가합니다.
- 입력 레이어에는 784개의 노드가 존재합니다. 28x28픽셀 이미지를 1 D 벡터로 변경하면 길이가 784가 되기 때문입니다. 하나의 노드에 입력은 1픽셀이며 이를 기반으로 계산되기를 원하기 때문에 그렇습니다.
- 은닉 레이어는 입력 수와 출력 레이어 노드들 사이의 임의의 숫자일 수 있지만 신경망 모델에서 가능한 결과가 10개가 존재하기 때문에 출력 레이어는 10이어야 합니다.
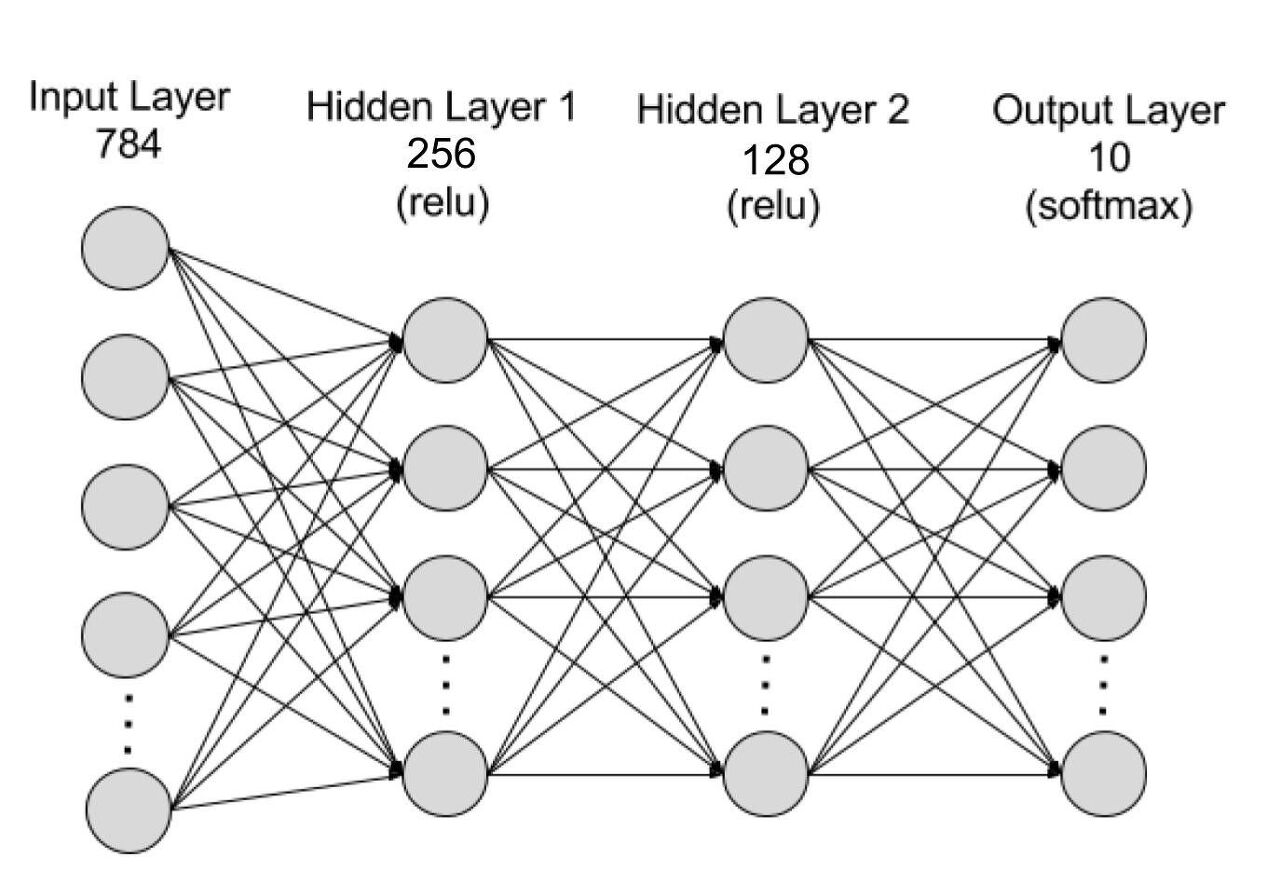
위의 그림과 같이 모델에는 신경망에서 활성화 함수 역할을 하는 ReLU 및 Softmax 함수와 과적합을 방지하기 위한 Dropout 함수가 필요합니다.(모델이 훈련 데이터와 너무 정렬되어 테스트에서 제대로 수행되지 않는 경우)
참고: Fashion MNIST 모델에는 3개의 숨겨진 레이어[256, 128, 64]가 있는 데, 나중에 모델의 정확도를 높이는 데 사용해야 하기 때문입니다.
단계 4: 모델 훈련
훈련 과정을 쉽게 개념화하려면 처음부터 3점슛을 시도하는 것같이 모델을 훈련 한다고 생각하세요 (분명히 Steph Curry처럼 매번 성공하지는 못할 것입니다 😉).
물론 공이 들어가는 데 얼마나 멀리 떨어져 있었는지 측정하기 위해 네트와 공 사이의 최단 거리를 사용합니다 → 손실이라고 하지요.
당신은 아마도 처음으로 공을 던져보고서 이 손실이 크다는 것을 깨달을 것입니다.
그리곤 기술을 변경해보고 손실을 낮추기 위해 노력하고 꽤 괜찮은 정확도를 얻을 때까지 이 주기를 계속 반복합니다.
이것은 신경망 모델이 훈련될 때 진행 되는 것과 유사합니다.
#training the model
total_training_loss = 0
for images, labels in trainloader:
images = images.view(images.shape[0], -1) optimizer.zero_grad()
logps = model(images)
loss = criterion(logps, labels)
loss.backward()
optimizer.step()total_training_loss += loss.item()위의 코드를 구체적으로:
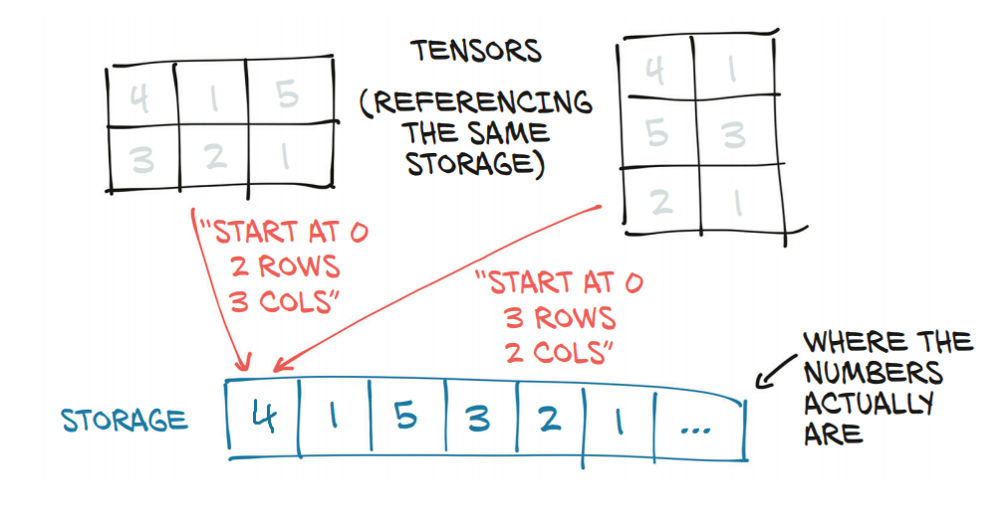
- 위에서 보듯이 2D 텐서를 1D 벡터로 변환하면 발생하는 일들입니다.
- 이미지와 해당 레이블은 훈련 데이터 세트에서 가져옵니다. 이미지는 현재 2D 텐서이지만 1D 벡터여야 하므로 평면화됩니다. 이 경우 해당 이미지의 크기를 취하는 데,
- 이미지는 1 x 28 x 28이고 images.shape[0]이 1인 것을 유지합니다. 그런 다음 나머지 차원을 하나의 숫자로 병합하여 적절한 크기(784 → 28 x 28)를 알아냅니다. 이 방법으로 모델은 1 x 28 x 28(2D 텐서)에서 1 x 74(1D 벡터)로 자체 조정되었습니다.
- 그런 다음 optimizer.zero_grad()를 사용하여 모델의 그래디언트를 0으로 설정합니다. 해당 그래디언트들은 오류/기울기의 변화와 관련하여 모든 가중치(두 뉴런 사이의 연결 강도를 제어하는 값)의 변화입니다. . 각 이전 에포크으로부터 그래디언트를 지우는 것이 필요합니다 그래야 결과가 서로 "충돌-collide"하지 않고 🚗 처리하기 어려운 오류가 발생하지 않습니다 😂.
- logps는 모든 이미지를 최초에 정의한 모델로 실행합니다.
- criterion = nn.NLLLoss() 함수는 "for" 루프 외부에서 정의되며 nn 모듈의 "Negative Log-Likelihood Loss"를 사용합니다. 이것은 나중에 보여지는 이미지와 레이블이 표시하는 것과 사이의 차이를 찾는 손실 변수에 사용됩니다. 기준이 NLLLoss를 사용하기 때문에 손실은 항상 음수이고 -1에 가까울수록 더 정확합니다. 4단계가 끝나면 전체 미니 배치의 총 손실을 배치 크기로 나눈 총 손실을 총 훈련 손실에 더합니다.
- 이 단계의 다음 부분은 backward() 함수를 사용하여 모델을 거꾸로 실행하고 이를 손실에 적용하는 것입니다(역전파).
- 또한 우리는 optimizer.step()을 사용하여 모델을 역방향으로 통과할 때 가중치를 업데이트합니다 → 경사 하강법이라고 합니다.
5단계: 모델 테스트
이제 모델을 훈련 했으니 모델이 unseen 데이터로 어떻게 동작하는지 이해하기 위해 이 모델을 실제로 테스트해야 합니다.
훈련 및 테스트 코드 블록은 상당히 유사하지만 테스트에는 현재 실행 중인 epoch의 결과, 손실 및 테스트 시 모델의 정확도를 출력하기 위해 더 많은 구문이 필요합니다.
#testing the model
total_testing_loss = 0
test_correct = 0
with torch.no_grad():
model.eval()
for images, labels in testloader:
images = images.view(images.shape[0], -1)
logps = model(images)
loss = criterion(logps, labels)
total_testing_loss += loss.item()
ps = torch.exp(model(images))
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
test_correct+=torch.mean(equals.type(torch.FloatTensor))
model.train()모델을 테스트할 때 두 가지 중요한 변수가 필요합니다. total_testing_loss와 모델이 테스트 데이터 세트 내에서 이미지를 올바르게 분류하는 횟수(정확도를 결정하는 데 사용됨)가 그것입니다.
- 이 코드는 테스트용이므로 그라디언트를 조정할 필요가 없으므로 torch.no_grad()를 사용하여 끕니다.
- 또한 테스트할 때 드롭아웃이 필요하지 않으므로 model.eval()을 사용하여 드롭아웃을 끄고 테스트 후에 다시 켭니다. 결과적으로 다음 에포크를 위해 루프의 맨 위로 돌아갈 때 다시 훈련을 위해 드롭아웃을 사용합니다.
- 다음 몇 줄은 testloader에서 이미지와 레이블을 가져와 1D 벡터로 보고 손실을 찾아 total_testing_loss에 추가하기 때문에 훈련 데이터 루프와 유사합니다.
- ps 변수는 이미지가 각 클래스일 확률을 가져옵니다. 그런 다음 각 이미지의 가장 높은 클래스 확률을 포함하는 ps.topk(1, dim=1)는 이미지의 가장 높은 확률(top_p)과 이미지와 관련된 클래스(top_class)의 두 가지로 나뉩니다.
- 다음으로 equal 변수가 True 또는 False로 설정됩니다. 예측 클래스와 레이블이 같으면 True(1)이고 그렇지 않으면 False(0)입니다. 모든 숫자가 추가되고 평균이 계산되어 total_correct에 합산 될 것입니다.
train_losses.append(total_training_loss / len(trainloader))
test_losses.append(total_testing_loss / len(testloader))print("Epoch: {}/{}.. ".format(e+1, epochs),
"Train Loss: {:.3f}.. ".format(train_losses[-1]),
"Test Loss: {:.3f}.. ".format(test_losses[-1]),
"Test Accuracy: {:.3f}".format(test_correct/len(testloader)))모델을 평가한 후 이전 코드 블록의 model.train() 바로 아래에서 해당 특정 에포크에 대한 평균 훈련 손실과 테스트 손실이 계산됩니다.
마지막으로 현재 에포크, 훈련 손실, 테스트 손실 및 정확도는 소수점 이하 3자리까지 소수점 형식으로 출력됩니다.
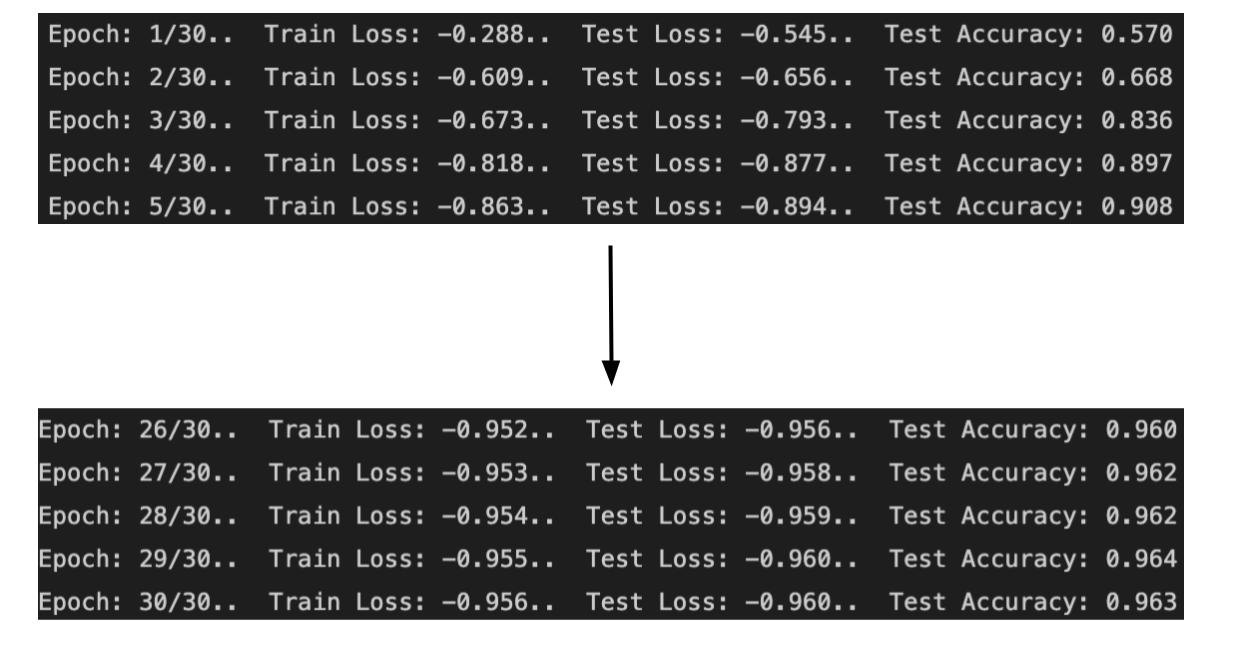
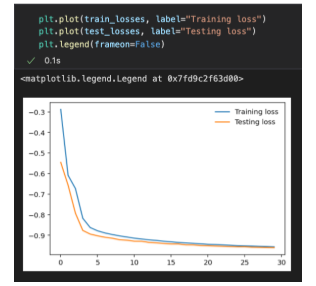
위의 내용은 30 epoch 이후에 인쇄된 내용입니다. 여기서 훈련 손실과 테스트 손실은 점점 0에 가까워지고 테스트 정확도는 점점 1에 가까워집니다.
알고 보니 3점 슛을 🏀를 반복적으로 쏘는 연습을 하는 것처럼 정확도가 높아졌습니다. 여기서 정확도는 57%에서 96%가 되었습니다.
참고: Fashion MNIST 모델의 경우 정확도는 21%에서 82%가 되었습니다.
이 정확도는 Number MNIST 모델보다 낮습니다. 이미지가 더 복잡하고 앞으로 몇 주 동안 자세히 살펴볼 이미지 분류 신경망인 CNN으로 더 잘 분류되기 때문입니다.
이 숫자를 이해하는 데 도움이 되도록 plt로 matplotlib.pyplot을 사용하여 간단한 그래프에 넣을 수 있습니다.
plt.plot(train_losses, label=”Training loss”)
plt.plot(test_losses, label=”Validation loss”)
plt.legend(frameon=False)위의 코드는 학습 손실과 테스트 손실을 비교하는 이중선 그래프를 출력합니다.
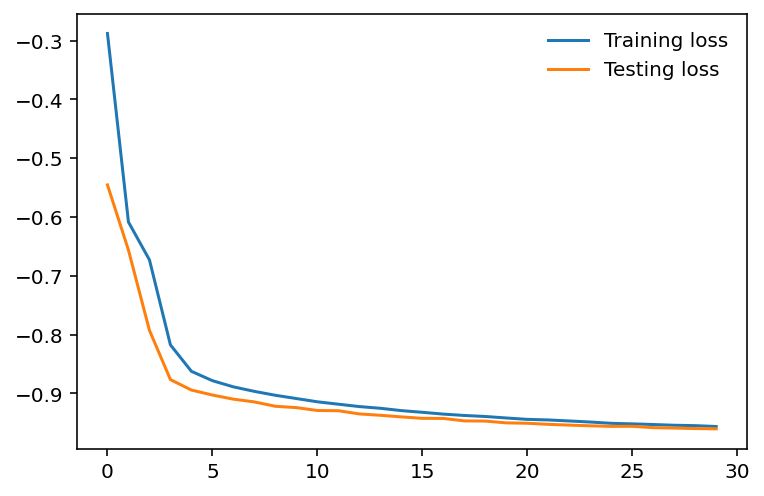
그래프에서 학습 손실과 테스트 손실은 감소하고 있으며 x축의 에포크 수가 증가함에 따라 서로 가까워지고 있습니다.
이것은 특히 과적합의 징후가 보이지 않기 때문에 우리 모델에 좋은 신호입니다.
- plt.plot()을 사용하여 에포크 수와 관련하여 훈련 손실과 테스트 손실에 대한 선을 그래프로 그렸습니다.
- 그런 다음 plt.legend()는 플롯에 범례를 제공합니다. 이 범례는 해당 함수의 frameon 속성이 False 로 설정되면 경계선이 없게 됩니다(주변에 상자가 없음).
단계 6: 시각화
훈련 및 테스트 후 얻을 수 있는 손실이 적고 정확도가 높기 때문에 모델이 작동한다는 것을 알고 있습니다. 이제 모델 출력을 시각화하는 예를 살펴보겠습니다.
images, labels = next(iter(testloader))
images.resize_(images.shape[0], 1, 784)ps = model(images[0,:])
helper.view_classify(images[0].view(1,28,28), ps)
print(labels[0])- 이 코드는 모든 이미지에서 진행 되며, 요약하면 각 에포크 후에 섞이게 됩니다. 그런 다음 모든 이미지의 크기를 1D 벡터로 조정합니다.
- ps 변수는 모델을 통해 모든 이미지를 넣고 각 클래스로 이미지의 확률을 가져옵니다.
helper.view_classify는 2개의 시각적 개체를 표시합니다. testloader의 이미지 집합에서 첫 번째 이미지와 ps를 표시하는 막대 그래프입니다.
마지막으로 모델이 올바른지 확인하기 위해 첫 번째 이미지에 해당하는 라벨을 인쇄합니다.
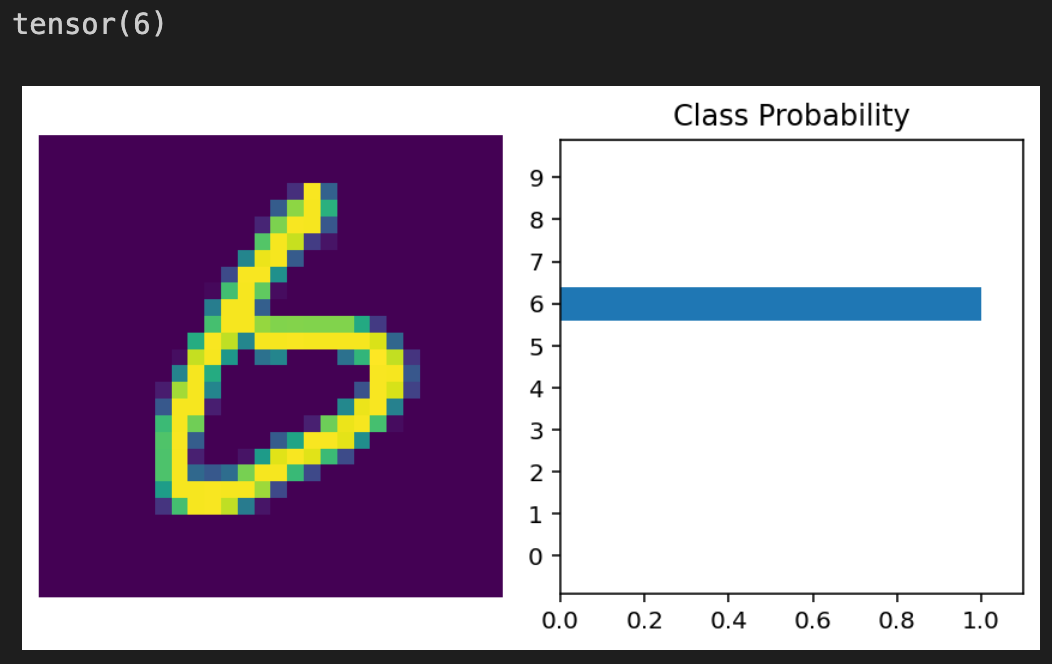
The image here shows a 6, which is confirmed with the model’s accurate results in the graph and “tensor(6)”
Fashion MNIST 모델은 시각화와 관련하여 동일한 코드를 사용하지만 다양한 데이터 세트에서 예상한 대로 출력이 다릅니다.

The image shows a shoe, which has a label/class of 7, and the model predicted it accurately once again 🥳
이상.
'머신러닝' 카테고리의 다른 글
| 파이썬과 머신러닝 (0) | 2024.10.10 |
|---|---|
| 파이썬 코드 예제 - 초보자를 위한 머신러닝 알고리즘 (1) | 2023.04.05 |
| C++에서 데이터 전처리 및 시각화 (1) | 2022.12.09 |
| 선형회귀와 그래프 (0) | 2022.10.12 |
| 선형회귀에 대한 고찰 (2) | 2022.10.07 |