
A Simple Guide to Machine Learning Visualisations - KDnuggets
Create simple, effective machine learning plots with Yellowbrick
www.kdnuggets.com
기계 학습 모델 개발의 중요한 단계는 성능을 평가하는 것입니다. 처리 중인 기계 학습 문제의 유형에 따라 일반적으로 이 단계를 처리하기 위한 일반적인 메트릭 선택이 필요 합니다.
하지만, 단순히 하나 또는 두 개의 숫자를 따로따로 보는 것만으로는 항상 올바른 모델 선택을 할 수 있는 것은 아닙니다. 예를 들어, 단일 오류 메트릭은 오류 분포에 대한 정보를 제공하지 않습니다.
이 적은 횟수를 가지고 모델이 크게 잘못된 것인지 아니면 작은 오류가 많이 발생하는 것인가? 와 같은 질문 대답이 될 수 없습니다.
모델 성능을 시각적으로 검사하는 것은 차트나 그래프 등이 단일 메트릭을 관찰할 때 놓칠 수 있는 정보를 나타낼 수 있으므로 필수적입니다.
Yellowbrick은 Scikit-learn을 사용하여 개발된 기계 학습 모델에 대한 풍부한 시각화를 쉽게 생성할 수 있도록 하는 전용 Python 라이브러리입니다.
아래 기사에서는 나는 이 편리한 기계 학습 도구를 소개하고 가장 일반적인 기계 학습 시각화를 위한 코드 샘플을 제공 해 드릴 것입니다.
혼동 행렬
혼동 행렬은 분류기의 예측이 얼마나 자주 맞는 지 시각적으로 평가하는 간단한 방법입니다.
혼동 행렬을 설명하기 위해 '당뇨병'-‘diabetes’ 이라는 데이터 세트를 사용하겠습니다. 이 데이터 세트는 체질량 지수, 2시간 혈청 인슐린 측정값 및 연령과 같은 환자에 대한 여러 기능과 환자가 당뇨병에 대해 양성 또는 음성 테스트를 받았는지 여부를 나타내는 열로 구성됩니다.
목표는 이 데이터를 사용하여 긍정적인 당뇨병 결과를 예측할 수 있는 모델을 구축하는 것입니다.
아래 코드는 Scikit-learn API를 통해 해당 데이터세트를 import 하고 있습니다.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(name='diabetes', return_X_y=True)이진 분류 문제에서는 모델이 만드는 예측에 대해 다음 네 가지 잠재적인 결과를 가집니다.
참 긍정(True positive): 모델이 긍정적인 결과를 올바르게 예측했습니다. 환자의 당뇨병 검사는 양성이었고 모델 예측은 양성이었습니다.
가양성(False-ositive): 모델이 긍정적인 결과를 잘못 예측했습니다. 환자의 당뇨병 검사는 음성이었지만 모델 예측은 양성이었습니다.
참음성(True negative): 모델이 부정적인 결과를 정확하게 예측했습니다. 환자의 당뇨병 검사는 음성이었고 모델 예측은 음성이었습니다.
거짓 음성(False-negative): 모델이 부정적인 결과를 잘못 예측했습니다. 환자의 당뇨병 검사는 양성이었지만 모델 예측은 음성이었습니다.
정오분류표는 이러한 각 가능한 결과의 수를 그리드로 시각화합니다. 아래 코드는 Yellowbrick ConfusionMatrix 시각화 도우미를 사용하여 모델에 대한 혼동 행렬을 생성한 것입니다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from yellowbrick.classifier import ConfusionMatrix
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
model = LogisticRegression()
cm = ConfusionMatrix(model)
cm.fit(X_train, y_train)
cm.score(X_test, y_test)
cm.show()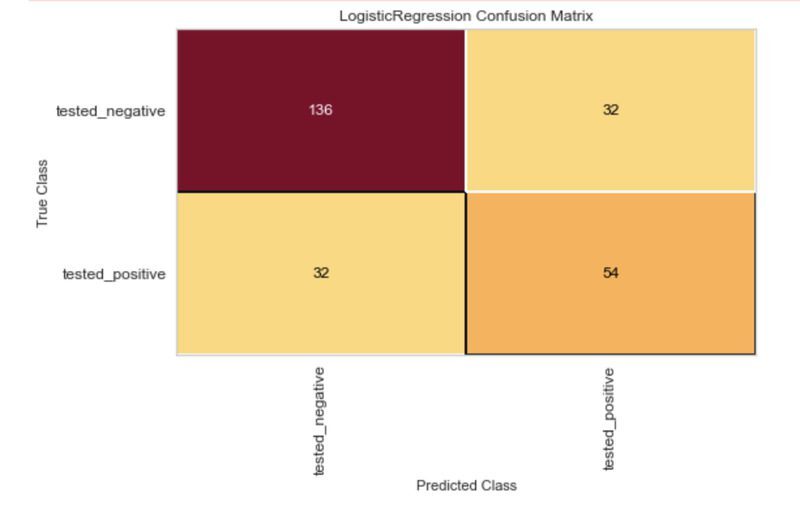
ROC 곡선
분류기의 초기 출력은 레이블이 아니라 특정 관찰이 특정 클래스에 속할 확률입니다.
이 확률은 그리고 임계값을 선택하여 클래스로 변환됩니다. 예를 들어, 환자가 양성 판정을 받을 확률이 0.5 이상이면 양성 레이블을 할당한다고 말할 수 있습니다.
모델, 데이터 및 사용 사례에 따라 특정 결과를 최적화하기 위해 임계값을 선택할 수 있습니다.
이 당뇨병 예에서 양성 결과를 놓치면 잠재적으로 생명을 위협할 수 있으므로 거짓 음성을 최소화하고자 합니다.
이 결과를 최적화하는 한 가지 방법은 분류기의 임계값을 변경하는 것이며 ROC 곡선은 이러한 균형을 시각화하는 한 가지 방법입니다.
아래 코드는 Yellowbrick을 사용하여 ROC 곡선을 구성합니다.
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from yellowbrick.classifier import ROCAUC
y = LabelEncoder().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
model = LogisticRegression()
visualizer = ROCAUC(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
ROC 곡선은 가양성 비율에 대한 참 긍정 비율을 표시합니다. 이 값을 사용하면 분류 임계값을 낮추거나 높이는 효과에 대한 평가를 내릴 수 있습니다.

정밀 재현율 곡선
ROC 곡선이 항상 분류기를 평가하는 최선의 방법은 아닙니다. 클래스가 불균형한 경우(한 클래스가 다른 클래스에 비해 더 많은 관찰을 가짐) ROC 곡선의 결과가 잘못될 수 있습니다.
이러한 상황에서는 정밀도-재현율 곡선이 더 나은 선택인 경우가 많습니다.
정밀도와 재현율이 의미하는 바를 빠르게 요약해 보겠습니다.
정밀도(Precision)는 모델이 포지티브 클래스를 올바르게 식별하는 정도를 측정합니다. 다시 말해서 긍정적인 클래스에 대한 모든 예측 중에서 실제로 맞는 것은 몇 개일까? 하는 것입니다.
재현율(Recall) 은 모델이 데이터 집합의 모든 긍정적인 관찰을 올바르게 예측하는 데 얼마나 좋은지 알려 줍니다.
정밀도와 재현율 사이에는 종종 절충점이 존재합니다. 예를 들어 우리는 재현율을 낮추는 대신 정밀도를 높일 수 있습니다.
정밀도-재현율 곡선은 서로 다른 분류 임계값에서 이러한 균형을 표시합니다.
아래 코드는 Yellowbrick 라이브러리를 사용하여 당뇨병 분류기에 대한 정밀 재현율 곡선을 생성합니다.
from yellowbrick.classifier import PrecisionRecallCurve
viz = PrecisionRecallCurve(LogisticRegression(random_state=42))
viz.fit(X_train, y_train)
viz.score(X_test, y_test)
viz.show()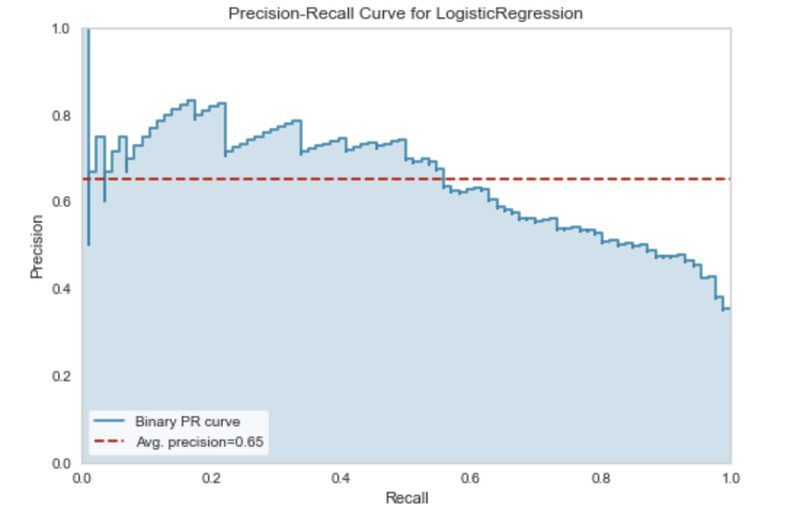
클러스터 간 거리
Yellowbrick 라이브러리에는 클러스터링 알고리즘을 분석하기 위한 시각화 도구 집합도 포함되어 있습니다.
클러스터링 모델의 성능을 평가하는 일반적인 방법은 클러스터 간 거리 맵을 사용하는 것입니다.
클러스터 간 거리 맵은 각 클러스터 중심의 임베딩을 플롯하고 클러스터 간의 거리와 구성원을 기반으로 하는 각 클러스터의 상대적 크기를 모두 시각화합니다.
특성(X)만 사용하여 당뇨병 데이터 세트를 클러스터링 문제로 전환할 수 있습니다.
데이터를 클러스터링하기 전에 인기 있는 엘보우 방법을 사용하여 최적의 클러스터 수를 찾을 수 있습니다.
Yellowbrick에는 이를 위한 다음의 메서드를 가지고 있습니다.
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,6))
visualizer.fit(X)
visualizer.show()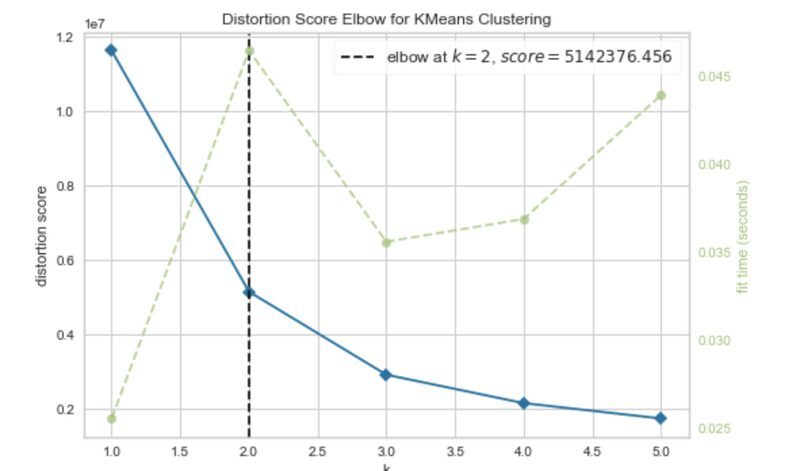
팔꿈치 곡선은 두 개의 군집이 최적임을 나타냅니다.
그럼 두 개의 클러스터를 선택하여 데이터 세트에 대한 클러스터 간 맵을 플로팅 해 봅시다.
from sklearn.cluster import KMeans
from yellowbrick.cluster import InterclusterDistance
model = KMeans(2)
visualizer = InterclusterDistance(model)
visualizer.fit(X)
visualizer.show()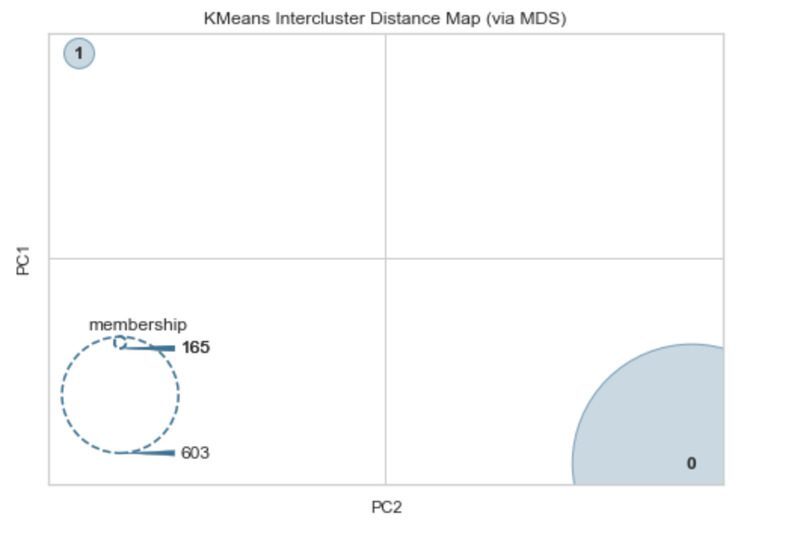
이를 통해 두 클러스터 사이에 많은 분리가 있음을 알 수 있습니다.
멤버십은 165개의 관찰이 있는 클러스터와 603이 있는 클러스터가 있음을 나타냅니다.
이것은 각각 268 및 500 관찰인 당뇨병 데이터 세트의 두 클래스의 균형에 매우 가깝습니다.
잔차 플롯
회귀 기반 기계 학습 모델에는 고유한 시각화 집합을 가지고 있습니다. Yellowbrick은 이러한 지원도 제공합니다.
회귀 문제에 대한 시각화를 설명하기 위해 Scikit-learn API를 통해 얻을 수 있는 당뇨병 데이터 세트의 변형을 사용할 것입니다.
이 데이터 세트는 이 기사의 앞부분에서 사용된 것과 유사한 기능을 가지고 있지만 목표는 기준선 이후 1년 후 질병 진행의 정량적 측정입니다.
from sklearn.datasets import load_diabetes
X, y = load_diabetes(return_X_y=True)
회귀에서 잔차 시각화는 모델의 성능을 분석하는 한 가지 방법입니다.
잔차는 관측된 값과 모델에서 예측한 값의 차이입니다.
이 것들은 회귀 모델의 오류를 수량화하는 한 가지 방법입니다.
아래 코드는 단순 회귀 모델에 대한 잔차 도표를 생성합니다.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from yellowbrick.regressor import residuals_plot
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, shuffle=True)
model = LinearRegression()
viz = residuals_plot(model, X_train, y_train, X_test, y_test)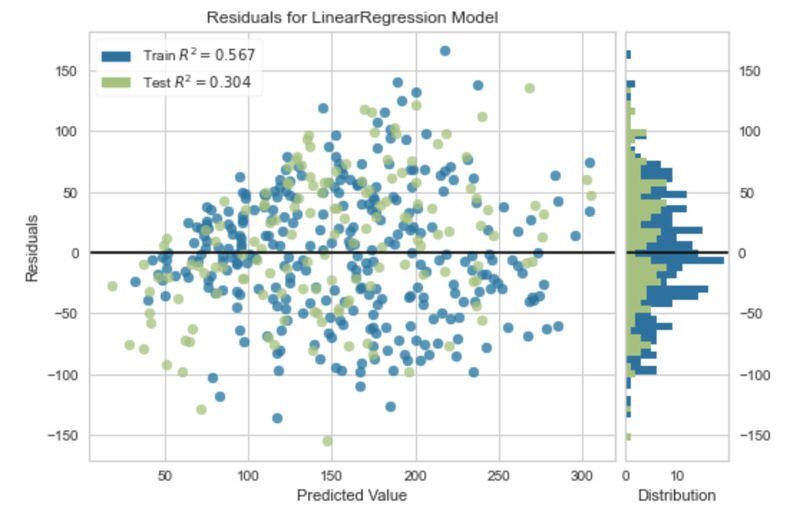
Yellowbrick 라이브러리에서 회귀 기반 모델에 사용할 수 있는 다른 시각화는 다음과 같습니다.
- 예측 오류 플롯- Prediction error plot.
- 알파 선택 - Alpha selection.
- 쿡의 거리 - Cook’s distance.
Yellowbrick Python 라이브러리는 Scikit-learn을 사용하여 개발된 모델에 대한 기계 학습 시각화를 생성하는 번개처럼 빠른 방법을 제공합니다.
모델 성능을 평가하기 위한 시각화 외에도 Yellowbrick에는 교차 검증, 학습 곡선 및 기능 중요도를 시각화하는 도구도 있습니다.
또한 텍스트 모델링 시각화를 위한 기능을 제공합니다.
기사에 설명된 대로 단일 평가 메트릭 모델이 유용할 수 있으며 경우에 따라 간단한 문제가 있고 다른 모델을 비교하는 경우 충분할 수 있습니다.
그러나 종종 모델 성능에 대한 시각화를 만드는 것은 기계 학습 모델이 얼마나 효과적인지에 대한 진정한 이해를 얻기 위한 중요한 추가 단계입니다.
단일 평가 메트릭에 대해 더 알고 싶다면 분류에 대한 평가 메트릭과 회귀에 대한 또 다른 평가 메트릭을 다루는 기사를 작성했습니다.
Rebecca Vickery는 데이터 분석, 기계 학습 및 데이터 엔지니어링에 대한 광범위한 경험을 가진 데이터 과학자입니다. SQL 경험 12년, Python, R, Apache Airflow 및 Google Analytics 4년 이상.
'머신러닝' 카테고리의 다른 글
| 피드포워드 신경망으로 숫자 및 의류 항목 분류 (0) | 2023.04.17 |
|---|---|
| 파이썬 코드 예제 - 초보자를 위한 머신러닝 알고리즘 (1) | 2023.04.05 |
| C++에서 데이터 전처리 및 시각화 (1) | 2022.12.09 |
| 선형회귀와 그래프 (0) | 2022.10.12 |
| 선형회귀에 대한 고찰 (3) | 2022.10.07 |